| 九种分布式ID解决方案 | 您所在的位置:网站首页 › stata string variable怎么解决 › 九种分布式ID解决方案 |
九种分布式ID解决方案
|
背景
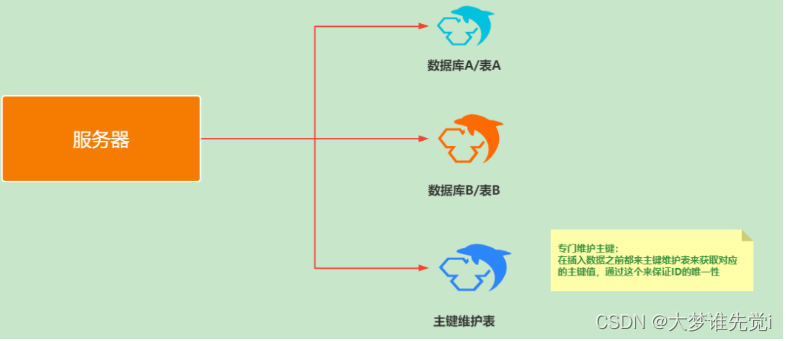
在复杂的分布式系统中,往往需要对大量的数据进行唯一标识,比如在对一个订单表进行了分库分表操作,这时候数据库的自增ID显然不能作为某个订单的唯一标识。除此之外还有其他分布式场景对分布式ID的一些要求: 趋势递增: 由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。单调递增: 保证下一个ID一定大于上一个ID,例如排序需求。信息安全: 如果ID是连续的,恶意用户的扒取工作就非常容易做了;如果是订单号就更危险了,可以直接知道我们的单量。所以在一些应用场景下,会需要ID无规则、不规则。 就不同的场景及要求,市面诞生了很多分布式ID解决方案。本文针对多个分布式ID解决方案进行介绍,包括其优缺点、使用场景及代码示例。 1、UUIDUUID(Universally Unique Identifier)是基于当前时间、计数器(counter)和硬件标识(通常为无线网卡的MAC地址)等数据计算生成的。包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,可以生成全球唯一的编码并且性能高效。 JDK提供了UUID生成工具,代码如下: import java.util.UUID; public class Test { public static void main(String[] args) { System.out.println(UUID.randomUUID()); } }输出如下 b0378f6a-eeb7-4779-bffe-2a9f3bc76380UUID完全可以满足分布式唯一标识,但是在实际应用过程中一般不采用,有如下几个原因: 存储成本高: UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。信息不安全: 基于MAC地址生成的UUID算法会暴露MAC地址,曾经梅丽莎病毒的制造者就是根据UUID寻找的。不符合MySQL主键要求: MySQL官方有明确的建议主键要尽量越短越好,因为太长对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。 2、数据库自增ID利用Mysql的特性ID自增,可以达到数据唯一标识,但是分库分表后只能保证一个表中的ID的唯一,而不能保证整体的ID唯一。为了避免这种情况,我们有以下两种方式解决该问题。 2.1、主键表通过单独创建主键表维护唯一标识,作为ID的输出源可以保证整体ID的唯一。举个例子: 创建一个主键表 CREATE TABLE `unique_id` ( `id` bigint NOT NULL AUTO_INCREMENT, `biz` char(1) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `biz` (`biz`) ) ENGINE = InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET =utf8;业务通过更新操作来获取ID信息,然后添加到某个分表中。 BEGIN; REPLACE INTO unique_id (biz) values ('o') ; SELECT LAST_INSERT_ID(); COMMIT;
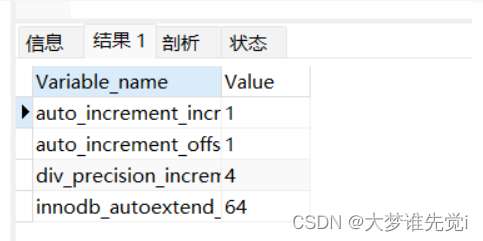
我们可以设置Mysql主键自增步长,让分布在不同实例的表数据ID做到不重复,保证整体的唯一。 如下,可以设置Mysql实例1步长为1,实例1步长为2。
查看主键自增的属性 show variables like '%increment%'
显然,这种方式在并发量比较高的情况下,如何保证扩展性其实会是一个问题。 3、号段模式号段模式是当下分布式ID生成器的主流实现方式之一。其原理如下: 号段模式每次从数据库取出一个号段范围,加载到服务内存中。业务获取时ID直接在这个范围递增取值即可。等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,新的号段范围是(max_id ,max_id +step]。由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新。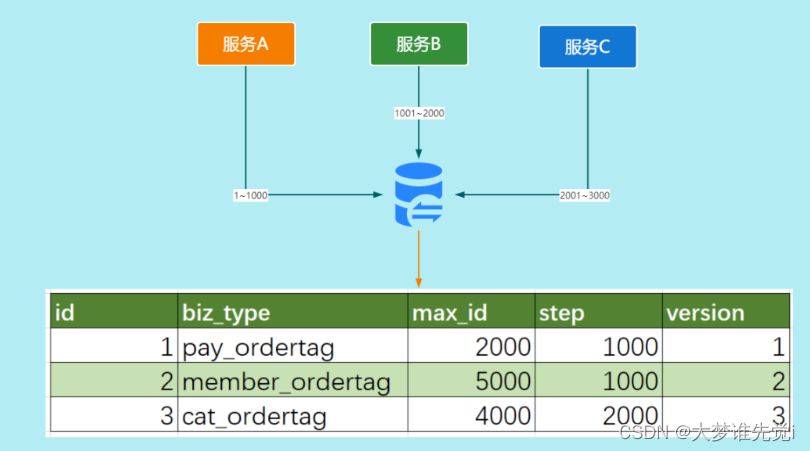
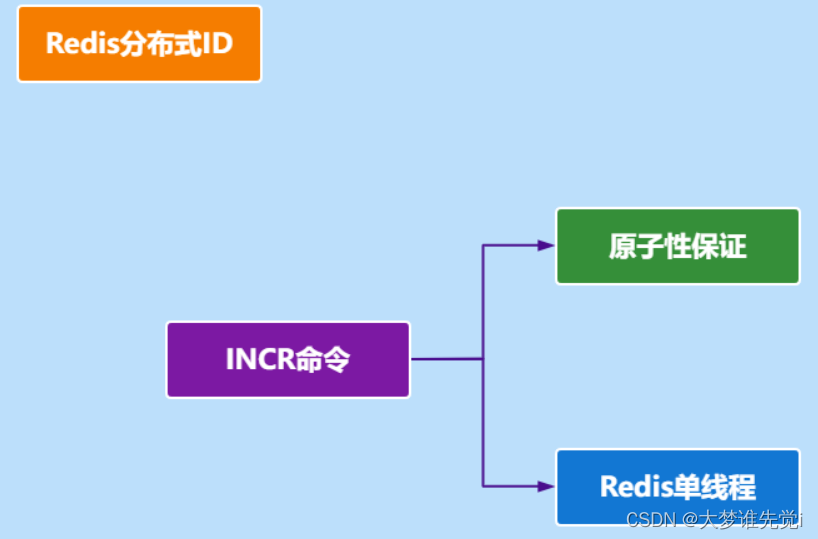
例如 (1,1000] 代表1000个ID,具体的业务服务将本号段生成1~1000的自增ID。表结构如下: CREATE TABLE id_generator ( id int(10) NOT NULL, max_id bigint(20) NOT NULL COMMENT '当前最大id', step int(20) NOT NULL COMMENT '号段的长度', biz_type int(20) NOT NULL COMMENT '业务类型', version int(20) NOT NULL COMMENT '版本号,是一个乐观锁,每次都更新version,保证并发时数据的正确性', PRIMARY KEY (`id`) )这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。但同样也会存在一些缺点比如:服务器重启,单点故障会造成ID不连续。 4、Redis INCR基于全局唯一ID的特性,我们可以通过Redis的INCR命令来生成全局唯一ID。
Redis分布式ID的简单案例 /** * Redis 分布式ID生成器 */ @Component public class RedisDistributedId { @Autowired private StringRedisTemplate redisTemplate; private static final long BEGIN_TIMESTAMP = 1659312000l; /** * 生成分布式ID * 符号位 时间戳[31位] 自增序号【32位】 * @param item * @return */ public long nextId(String item){ // 1.生成时间戳 LocalDateTime now = LocalDateTime.now(); // 格林威治时间差 long nowSecond = now.toEpochSecond(ZoneOffset.UTC); // 我们需要获取的 时间戳 信息 long timestamp = nowSecond - BEGIN_TIMESTAMP; // 2.生成序号 --》 从Redis中获取 // 当前当前的日期 String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd")); // 获取对应的自增的序号 Long increment = redisTemplate.opsForValue().increment("id:" + item + ":" + date); return timestamp |

【本文地址】